Differences between Clustering, Regression, and Classification in Machine Learning
Which One Should You Use?
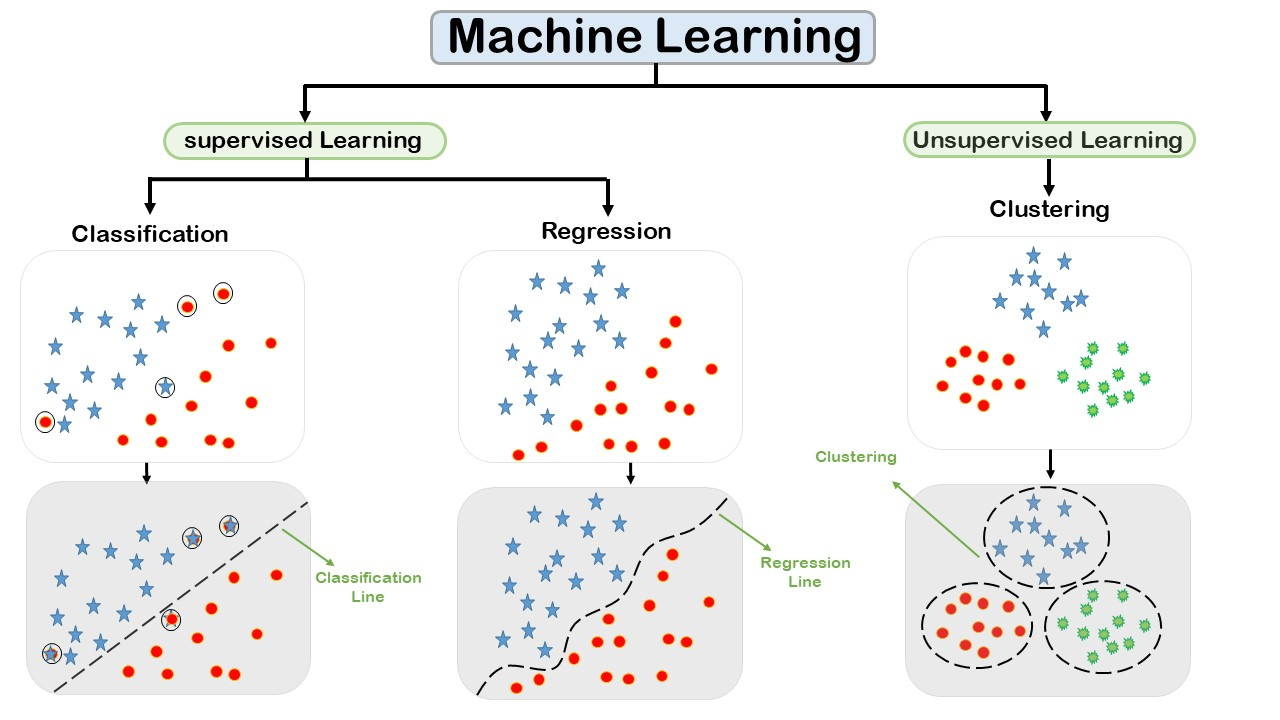
Machine learning is an effective tool which assists us in data analysis, predictions, and pattern discovery. However, when there are numerous kinds of algorithms, it is easy to lose our way and turn the difference between clustering, regression and classification into a confusion. Assuming you have been studying machine learning, you are familiar with such names as clustering, regression, and classification. These are three significant categories of tasks in machine learning although these are confused. The definition was well defined stating definitions, examples and the manner in which they can be distinguished.
1. Regression: Predicting Continuous Values
Regression is employed when we are interested in predicting a number, when the response (also known as the target or label) is a real number. It answers questions like “How much?”, “How many?”, or “What will the value be?”
Example:
Predicting the price of an object or place based on features like size, location, and quality.
Estimating the temperature for the next day
Popular Regression Algorithms:
Popular regression algorithms include Linear Regression for modeling linear relationships, Polynomial Regression for capturing non-linear trends, Support Vector Regression for high-dimensional predictions, and Decision Tree Regression for handling both linear and non-linear data through rule-based splits.
2. Classification: Predicting Categories
Classification is used when we want to predict a user’s labeled or category. Classification is used when the output variable is categorical. It answers questions like “Which class?” You train the model to assign inputs to one of several classes or categories.
Example:
- Email identification: Email is Spam or Email Not Spam
- Human health diagnosis: Disease, No Disease, or Healthy
- Analysis on any collected labeled dataset
Popular classification algorithms include Random Forest for ensemble-based predictions, Support Vector Machine for finding optimal decision boundaries, and Decision Trees for making decisions through hierarchical splits.
3. Clustering: Grouping Without Labels
Clustering is used when we want to partition similar things into groups, but we do not know beforehand what the classes should be. It is used on unlabelled data. Clustering is an unsupervised learning technique, used in case data is unclassified. An algorithm attempts to group likewise information points dependably on the groundwork or likenesses. It does not know the output in question ahead of time.
Example:
- Customer segmentation in marketing
- Grouping similar news articles
- Organizing similar products together
- Gaussian Mixture Models
- DBSCAN
- Hierarchical Clustering
- K-Means Clustering
| Feature | Regression | Classification | Clustering |
| Output | A number | A category or label | A group or cluster |
| Data Type | Labeled data | Labeled data | Unlabeled data |
| Supervision | Supervised learning | Supervised learning | Unsupervised learning |
| Example | Predicting house price | Detecting spam emails | Grouping customers |
Use regression when your target is a real number (e.g., price, age, salary).
Use classification when your goal is to assign items to categories (e.g., diagnosis, spam detection, sentiment analysis).